Thesis projects
Hello everyone,
NLP researchers at UvA have proposed some exciting thesis projects for you! You can find them below. If you are interested in any of the projects, please contact the prospective supervisor directly.
Lexical ambiguity and polysemy with density matrices
Supervisors: Martha Lewis (ILLC) and Ekaterina Shutova (ILLC)
Description
Polysemy is the phenomenon that words adopt different meanings according to their contexts of use. This can range from clear-cut ambiguity such as ‘diamond’ with the meaning ‘gemstone’ or ‘shape’ to more subtle polysemous meaning such as ‘window’ in ‘Marcelle broke the window’ (the glass) or ‘The bird flew out of the window’ (the opening). Approaches to modelling polysemy in distributional semantics include building one representation that can represent all senses at once, or alternatively, representing different senses as separate vectors.
A recent extension to standard vector-based semantics uses the notion of a density matrix from quantum theory to encode a statistical ensemble of vectors. This has been posited to model lexical ambiguity (Piedeleu et al., 2016) and entailment (Sadrzadeh et al., 2018, Bankova et al., 2019, Lewis 2019). Since density matrices can encode a number of vectors within one representation, they form a middle ground between the two approaches described above.
Furthermore, density matrix representations can be understood within a tensor-based compositional distributional semantic model (Coecke et al., 2010, Baroni and Zamparelli 2010). The resolution of ambiguous terms in context can therefore be realised within the composition of strings of words into phrases.
This project will investigate different ways of building density matrix representations of words, including designing novel neural network architectures inspired by the density matrix approach. Ways of composing the matrices to form phrase and sentence representations will also be a topic of research. Comparisons will be made with recent work on contextualised word representations (Peters et al, 2018, Devlin et al, 2019), and the project would contribute to this line of research by designing new models. The representations and composition methods will be assessed against datasets that require disambiguation, such as for Mitchell and Lapata (2008), Grefenstette and Sadrzadeh (2011), or WiC: The Word-in-Context Dataset (https://pilehvar.github.io/).
Following on from this, the use of density matrices to encode polysemy can be investigated within the context of metaphor. Metaphor can be viewed as a type of polysemy (Peters and Peters, 2000), and the effectiveness of disambiguating literal and metaphorical senses of a word has been shown in Gutierrez et al., (2016). This part of the project will investigate the effectiveness of using density matrix representations in metaphor identification and/or interpretation.
This is an ambitious project, suitable for students with a background and interest in mathematics and machine learning and keen to conduct novel research. We hope that it would lead to a publication.
What are our expectations of the student?
- Independent and proactive attitude and an interest in artificial intelligence
- Solid maths background: calculus, linear algebra, probability and statistics
- Advanced programming skills (algorithms and data structures; ideally experience with Pytorch or other deep learning libraries)
- Knowledge and skill in developing and applying machine learning algorithms (particularly, interest and experience in deep learning)
- Good familiarity with and experience in NLP; but don’t worry we will help you to fill in the gaps.
Further reading:
Bankova, D., Coecke, B., Lewis, M., & Marsden, D. (2019). Graded hyponymy for compositional distributional semantics. Journal of Language Modelling, 6(2), 225-260. http://jlm.ipipan.waw.pl/index.php/JLM/article/view/230
Baroni, M., & Zamparelli, R. (2010). Nouns are vectors, adjectives are matrices: Representing adjective-noun constructions in semantic space. In Proceedings of the 2010 Conference on Empirical Methods in Natural Language Processing (pp. 1183-1193). Association for Computational Linguistics. https://www.aclweb.org/anthology/D10-1115
Coecke, B., Sadrzadeh, M., & Clark, S. (2010). Mathematical Foundations for a Compositional Distributed Model of Meaning. Lambek Festschrift, Linguistic Analysis, vol. 36. https://arxiv.org/abs/1003.4394
Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2019, June). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers) (pp. 4171-4186). https://arxiv.org/abs/1810.04805
Grefenstette, E., & Sadrzadeh, M. (2011, July). Experimental support for a categorical compositional distributional model of meaning. In Proceedings of the Conference on Empirical Methods in Natural Language Processing (pp. 1394-1404). Association for Computational Linguistics. https://www.aclweb.org/anthology/D11-1129
Gutierrez, E. D., Shutova, E., Marghetis, T., & Bergen, B. (2016, August). Literal and metaphorical senses in compositional distributional semantic models. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) (pp. 183-193). https://www.aclweb.org/anthology/P16-1018
Lewis, M., (2019). Compositional Hyponymy with Positive Operators. To appear at RANLP 2019. (preprint available on request)
Mitchell, J., & Lapata, M. (2008, June). Vector-based models of semantic composition. In proceedings of ACL-08: HLT (pp. 236-244). https://www.aclweb.org/anthology/P08-1028
Peters, W., & Peters, I. (2000, May). Lexicalised Systematic Polysemy in WordNet. In LREC. http://www.lrec-conf.org/proceedings/lrec2000/pdf/148.pdf
Peters, M. E., Neumann, M., Iyyer, M., Gardner, M., Clark, C., Lee, K., & Zettlemoyer, L. (2018). Deep contextualized word representations. In Proceedings of NAACL-HLT (pp. 2227-2237). https://arxiv.org/abs/1802.05365
Piedeleu, R., Kartsaklis, D., Coecke, B., & Sadrzadeh, M. (2015). Open System Categorical Quantum Semantics in Natural Language Processing. In 6th Conference on Algebra and Coalgebra in Computer Science (CALCO 2015). Schloss Dagstuhl-Leibniz-Zentrum fuer Informatik. https://arxiv.org/abs/1502.00831
Sadrzadeh, M., Kartsaklis, D., & Balkır, E. (2018). Sentence entailment in compositional distributional semantics. Annals of Mathematics and Artificial Intelligence, 82(4), 189-218.
Citation embeddings
Supervisor: Giovanni Colavizza and Nees J. van Eck (CWTS, Leiden University)
Description
Scientific publications contain large amounts of citations to other publications. Citations occur within the text of publications, in sentences or paragraphs named citation contexts. In this project, we will consider the citation contexts from where a given publication is cited as a timed stream. We will thus explore the following questions: A) can we embed citations into a low-dimensional space using their citation contexts? Which embedding method is most suited for the task (e.g., Word2Vec, GloVe, BERT)? How is the resulting space configured? For example, can we cluster citations by their purpose, by the contribution of the cited paper (e.g., a method or a claim) or by where they occur in the text (e.g., section)? B) How is the citation embedding of highly-cited papers changing over time, as the paper gets older? C) Are citation embeddings sensitive to different academic disciplines? D) Are citation embeddings predictive of future citations? Understanding citation contexts is crucial to improve scholarly information retrieval and for the automation of science. It can also be relevant to improve existing visualization tools to map science. For this project, you will use data from the full-text of all Elsevier publications (>10M) and the PubMed Open Access collection (>2M). The project is done in collaboration with the Centre for Science and Technology Studies (CWTS), Leiden University, which provides access to data and expertise in science studies.
Further reading:
Berger, Matthew, Katherine McDonough, and Lee M. Seversky. 2017. “Cite2vec: Citation-Driven Document Exploration via Word Embeddings.” https://doi.org/10.1109/TVCG.2016.2598667. He, Jiangen, and Chaomei Chen. 2017. “Understanding the Changing Roles of Scientific Publications via Citation Embeddings” https://arxiv.org/abs/1711.05822. ———. 2018. “Temporal Representations of Citations for Understanding the Changing Roles of Scientific Publications.” https://doi.org/10.3389/frma.2018.00027. Small, Henry, Kevin W. Boyack, and Richard Klavans. 2019. “Citations and Certainty: A New Interpretation of Citation Counts.” https://doi.org/10.1007/s11192-019-03016-z. Tshitoyan, Vahe, John Dagdelen, Leigh Weston, Alexander Dunn, Ziqin Rong, Olga Kononova, Kristin A. Persson, Gerbrand Ceder, and Anubhav Jain. 2019. “Unsupervised Word Embeddings Capture Latent Knowledge from Materials Science Literature.” https://doi.org/10.1038/s41586-019-1335-8.
Towards machine-generated review articles
Supervisor: Giovanni Colavizza
Review articles play a crucial role in summarizing and consolidating previous scientific results. Given the growing number of scientific articles being published every year, their importance is growing as well. Systematic review articles are particularly vital in medicine, in order to consolidate trials on a given topic. Unfortunately, writing a review article is an increasingly prohibitive task for researchers, in terms of time and effort involved. AI can play a significant role into aiding researchers performing that task and, in the limit, fully automating it. In this project, we will explore (some of) the following: A) learn to rank literature which made it into a review article. This covers the task of selecting literature for a review article. B) Explore or devise an extractive summarization baseline for the task of assembling a set of sentences or paragraphs from the selected articles, which are good candidates to be paraphrased into a review article. Extractive summarization, as the name suggests, uses chunks of text taken from the articles to be summarized. C) Explore or devise an abstractive summarization method to summarize a set of articles using new, machine-generated text. For this project, you will use data from the full-text of all Elsevier publications (>10M) and the PubMed Open Access collection (>2M). The project is done in collaboration with the Centre for Science and Technology Studies (CWTS), Leiden University, which provides access to data and expertise in science studies.
Further reading:
Belter, Christopher W. 2016. “Citation Analysis as a Literature Search Method for Systematic Reviews.” http://onlinelibrary.wiley.com/doi/10.1002/asi.23605/pdf. Cohan, Arman, and Nazli Goharian. 2017. “Scientific Document Summarization via Citation Contextualization and Scientific Discourse.” https://doi.org/10.1007/s00799-017-0216-8. Conroy, John M., and Sashka T. Davis. 2017. “Section Mixture Models for Scientific Document Summarization.” https://doi.org/10.1007/s00799-017-0218-6. Yasunaga, Michihiro, Rui Zhang, Kshitijh Meelu, Ayush Pareek, Krishnan Srinivasan, and Dragomir Radev. 2017. “Graph-Based Neural Multi-Document Summarization.” https://arxiv.org/abs/1706.06681. Keneshloo, Yaser, Naren Ramakrishnan, and Chandan K. Reddy. 2018. “Deep Transfer Reinforcement Learning for Text Summarization.” http://arxiv.org/abs/1810.06667. Merity, Stephen, Caiming Xiong, James Bradbury, and Richard Socher. 2016. “Pointer Sentinel Mixture Models.” https://arxiv.org/abs/1609.07843. O’Mara-Eves, Alison, James Thomas, John McNaught, Makoto Miwa, and Sophia Ananiadou. 2015. “Using Text Mining for Study Identification in Systematic Reviews: A Systematic Review of Current Approaches.” https://doi.org/10.1186/2046-4053-4-5. Park, Donghyeon, Yonghwa Choi, Daehan Kim, Minhwan Yu, Seongsoon Kim, and Jaewoo Kang. 2019. “Can Machines Learn to Comprehend Scientific Literature?” https://doi.org/10.1109/ACCESS.2019.2891666. Parveen, Daraksha, Mohsen Mesgar, and Michael Strube. 2016. “Generating Coherent Summaries of Scientific Articles Using Coherence Patterns.” https://www.aclweb.org/anthology/D/D16/D16-1074.pdf. Tshitoyan, Vahe, John Dagdelen, Leigh Weston, Alexander Dunn, Ziqin Rong, Olga Kononova, Kristin A. Persson, Gerbrand Ceder, and Anubhav Jain. 2019. “Unsupervised Word Embeddings Capture Latent Knowledge from Materials Science Literature.” https://doi.org/10.1038/s41586-019-1335-8.
Predicting citations in Wikipedia
Supervisor: Giovanni Colavizza, Ludo Waltman (CWTS, Leiden University) and Bob West (EPFL)
Description
Wikipedia is one of the main access points to scientific knowledge for the general public. Educators, students, professionals use it regularly to check facts and get insights. Yet little is known on which scientific publications are referred from Wikipedia, and thus used to support the claims it contains. In this project, we will first consider citations with identifiers from Wikipedia (this data is already made available) and link them with large-scale citation indexes (e.g., Microsoft Academic). The two key questions we will need to answer are: which publications make it into Wikipedia (e.g., highly cited ones or recent ones?) and when are they added (how long after publication?). This analysis will be performed by research field. Secondly, we will improve on existing art to detect when a citation might be needed from a Wikipedia statement, and propose a list of possible candidates for a new citation. This work will be of great value to Wikipedia editors and can impact the contents of the encyclopedia by growing and de-biasing the evidence base it relies upon. For this project, you will use data from Wikipedia and Microsoft Academic. The project is done in collaboration with the Centre for Science and Technology Studies (CWTS), Leiden University, which provides access to citation data and expertise in science studies, and with the Data Science Laboratory of the EPFL, which provides Wikipedia data and expertise. The project will be conducted in coordination with Wikimedia Foundation Research.
Further reading:
Lemmerich, Florian, Diego Sáez-Trumper, Robert West, and Leila Zia. 2018. “Why the World Reads Wikipedia: Beyond English Speakers.” http://arxiv.org/abs/1812.00474. Redi, Miriam, Besnik Fetahu, Jonathan Morgan, and Dario Taraborelli. 2019. “Citation Needed: A Taxonomy and Algorithmic Assessment of Wikipedia’s Verifiability.” http://arxiv.org/abs/1902.11116. Thompson, Neil, and Douglas Hanley. 2017. “Science Is Shaped by Wikipedia: Evidence from a Randomized Control Trial.” https://doi.org/10.2139/ssrn.3039505.
Optical Character Recognition (OCR) unsupervised post-correction
Supervisor: Giovanni Colavizza, Kasra Hosseini and Mariona Coll Ardanuy (The Alan Turing Institute)
Description
Increasing amounts of historical texts are being digitized and OCRed, that is to say their text extracted from the images. Notable examples include newspapers and books. OCR is an error-prone procedure, in part due to the challenges of historical texts, such as lack of vocabulary uniformity. Traditionally, OCRed texts have been post-corrected using complex sets of rules or by hand, or not at all. More recently, promising results from state-of-the-art deep learning language models encourage the exploration of fully unsupervised OCRed text post-correction: by leveraging a trained language model, the post-correction can be performed by suitably consolidating the original vocabulary. Positive results would have a large impact on the accessibility of historical texts in the digital humanities and heritage sectors. The project aims at exploring suitable language models for the task at hand (Word2Vec, GloVe, Flair, BERT and more), at devising an appropriate measure for detecting tokens with errors and at applying it for post-correcting existing texts. The project uses data (mainly 19th-century newspapers in English) and benefits from experts from the Living with Machines project, based the The Alan Turing Institute and the British Library.
Further reading:
Evershed, John, and Kent Fitch. 2014. “Correcting Noisy OCR: Context Beats Confusion.” https://doi.org/10.1145/2595188.2595200. Hakala, Kai, Aleksi Vesanto, Niko Miekka, Tapio Salakoski, and Filip Ginter. 2019. “Leveraging Text Repetitions and Denoising Autoencoders in OCR Post-Correction.” http://arxiv.org/abs/1906.10907. Hill, Mark J, and Simon Hengchen. 2019. “Quantifying the Impact of Messy Data on Historical Text Analysis.” https://doi.org/10.1093/llc/fqz024.
Multi-scale dynamic topic modelling for historical newspapers
Supervisor: Giovanni Colavizza and Kasra Hosseini (The Alan Turing Institute)
Description
Increasing amounts of historical texts are being digitized and their texts extracted. Notable examples include newspapers and books. Detecting meaningful topics for these large text collections remains an open challenge. In particular, topics at multiple scales are necessary in order to allow for a richer exploration of these contents. Further challenges include the need to account for time, as historical collections can span decades or even centuries. The project aims at exploring a variety of unsupervised topic modelling techniques, including dynamic topic models, structured topic models and neural topic models, in order to devise and deploy a suitable topic model for a large collection of 19th-century newspapers in English. Requirements include accounting for topic change over time and for different topic scales. The project uses data and benefits from experts from the Living with Machines project, based the The Alan Turing Institute and the British Library.
Further reading:
Blei, David M., and John D. Lafferty. 2006. “Dynamic Topic Models.” http://dl.acm.org/citation.cfm?id=1143859. Blei, David M., Andrew Y. Ng, and Michael I. Jordan. 2003. “Latent Dirichlet Allocation.” http://www.jmlr.org/papers/volume3/blei03a/blei03a.pdf. Dieng, Adji B., Francisco J. R. Ruiz, and David M. Blei. 2019a. “Topic Modeling in Embedding Spaces.” http://arxiv.org/abs/1907.04907. ———. 2019b. “The Dynamic Embedded Topic Model.” http://arxiv.org/abs/1907.05545. Gerlach, Martin, Tiago P Peixoto, and Eduardo G Altmann. 2018. “A Network Approach to Topic Models.” https://arxiv.org/abs/1708.01677. Roberts, Margaret E., Brandon M. Stewart, and Edoardo M. Airoldi. 2013. “A Model for Text Experimentation in the Social Sciences.” https://scholar.princeton.edu/sites/default/files/bstewart/files/stm.pdf. Wallach, Hanna M., Iain Murray, Ruslan Salakhutdinov, and David Mimno. 2009. “Evaluation Methods for Topic Models.” http://dl.acm.org/citation.cfm?id=1553515. Wang, Jacob Su. 2017. “Topic Modeling: A Complete Introductory Guide.” http://suwangcompling.com/wp-content/uploads/2017/04/intro_topicmodel_jsw.pdf.
Digital Humanities shared tasks: Semantic change and Named Entity Recognition
Supervisor: Giovanni Colavizza, Kaspar Beelen and Mariona Coll Ardanuy (The Alan Turing Institute)
Description
In 2020, two novel NLP challenges will be released with a focus on digital humanities and historical data: Semantic change (SemEval 2020) and (multilingual) Named Entity Recognition (Clef 2020). Shared tasks are released with an annotated dataset which you can use to train and test novel models: this project thus will exclusively focus on beating the state of the art on one of the two tasks, the one you prefer. Part of the project will entail submitting to the conference and, if accepted, publish and attending in person. Semantic change focuses on detecting a shift in word meaning over time, a task that has attracted attention in recent years and is just starting to be applied on historical data (read: over centuries of changes, instead of years). Named Entity Recognition and Disambiguation (NERD) is a known task in NLP, where the goal is to detect mentions of named entities (e.g., persons or places) in texts, and link them to unique identifiers. NERD poses several challenges when applied to historical texts, including bad OCR quality and missing identifiers in gazetteers. Both semantic change and NERD state of the art models presently work with deep learning architectures and pre-trained language models, yet it is unknown which architecture will perform best at these challenges (it’s the first time they are proposed!)
Further reading:
NERD:
Coll Ardanuy, Mariona, Jürgen Knauth, Andrei Beliankou, Maarten van den Bos, and Caroline Sporleder. 2016. “Person-Centric Mining of Historical Newspaper Collections.” https://doi.org/10.1007/978-3-319-43997-6_25. Ehrmann, Maud, Giovanni Colavizza, Yannick Rochat, and Frédéric Kaplan. 2016. “Diachronic Evaluation of NER Systems on Old Newspapers.” https://infoscience.epfl.ch/record/221391. Shen, Yanyao, Hyokun Yun, Zachary C. Lipton, Yakov Kronrod, and Animashree Anandkumar. 2017. “Deep Active Learning for Named Entity Recognition.” http://arxiv.org/abs/1707.05928. Won, Miguel, Patricia Murrieta-Flores, and Bruno Martins. 2018. “Ensemble Named Entity Recognition (NER): Evaluating NER Tools in the Identification of Place Names in Historical Corpora.” https://doi.org/10.3389/fdigh.2018.00002.
Semantic change:
Anderson, Ashton, Dan McFarland, and Dan Jurafsky. 2012. “Towards a Computational History of the ACL: 1980-2008.” http://dl.acm.org/citation.cfm?id=2390510. Hamilton, William L., Jure Leskovec, and Dan Jurafsky. 2016. “Cultural Shift or Linguistic Drift? Comparing Two Computational Measures of Semantic Change.” http://arxiv.org/abs/1606.02821. Jo, Eun Seo, and Mark Algee-Hewitt. 2018. “The Long Arc of History: Neural Network Approaches to Diachronic Linguistic Change.” https://www.jstage.jst.go.jp/article/jjadh/3/1/3_1/_article. Kutuzov, Andrey, Lilja Øvrelid, Terrence Szymanski, and Erik Velldal. 2018. “Diachronic Word Embeddings and Semantic Shifts: A Survey.” http://arxiv.org/abs/1806.03537. Lansdall-Welfare, Thomas, Saatviga Sudhahar, James Thompson, Justin Lewis, FindMyPast Newspaper Team, and Nello Cristianini. 2017. “Content Analysis of 150 Years of British Periodicals.” https://doi.org/10.1073/pnas.1606380114. Rudolph, Maja, and David Blei. 2018. “Dynamic Embeddings for Language Evolution.” https://doi.org/10.1145/3178876.3185999. Rule, Alix, Jean-Philippe Cointet, and Peter S. Bearman. 2015. “Lexical Shifts, Substantive Changes, and Continuity in State of the Union Discourse, 1790–2014.” https://doi.org/10.1073/pnas.1512221112. Tahmasebi, Nina, Lars Borin, and Adam Jatowt. 2018. “Survey of Computational Approaches to Diachronic Conceptual Change.” http://arxiv.org/abs/1811.06278. Tang, Xuri. 2018. “A State-of-the-Art of Semantic Change Computation.” http://arxiv.org/abs/1801.09872.
Transfer Learning for historical texts: Evaluating the impact of OCR and language change on the transferability of language models
Supervisor: Giovanni Colavizza and Daniel van Strien (British Library)
Pre-trained language models utilising deep learning have led to state of the art results in many NLP tasks. Compared to Word2Vec and other word embedding models, new deep learning language models, such as ULMFiT, ELMo and BERT are able to capture richer representations of language features. A major benefit of these models is that they can be trained on large corpora without supervision. These pre-trained language models have subsequently been made available for others to use. This has had the to a reduction in the amount of trained labels required for NLP tasks and more efficient training (both in time and cost) and increased accuracy of models.
There are a number of potential challenges in applying these models in a digital humanities context. Firstly, pre-trained language models are trained on modern text, largely gathered from the Web. Secondly, these pre-trained language models are not trained on text produced as a result of OCR. This project aims to explore the impact of these two challenges. More specifically it would be suggested that the student explores the use of ULMFiT and BERT on classification and Named Entity Recognition tasks. This project would explore how well these models perform on historic texts with and without the use of fine tuning these models. Other NLP tasks and models could be explored depending on the students’ interest. There are a range of outputs that could emerge from the project, including publications offering initial guidance for other researchers on the most effective approach to utilising these models for historic OCR text. The project uses data and benefits from experts from the Living with Machines project, based the The Alan Turing Institute and the British Library.
Further reading:
Ruder, S. (2019). NLP’s ImageNet moment has arrived. [online] Sebastian Ruder. Available at: http://ruder.io/nlp-imagenet.
‘An Embarrassingly Simple Approach for Transfer Learning from Pretrained Language Models’. GroundAI. https://www.groundai.com/project/an-embarrassingly-simple-approach-for-transfer-learning-from-pretrained-language-models/1.
Devlin, Jacob, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. ‘BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding’. http://arxiv.org/abs/1810.04805.
Howard, Jeremy, and Sebastian Ruder. ‘Universal Language Model Fine-Tuning for Text Classification’. http://arxiv.org/abs/1801.06146.
Peters, Matthew E., Sebastian Ruder, and Noah A. Smith. ‘To Tune or Not to Tune? Adapting Pretrained Representations to Diverse Tasks’. http://arxiv.org/abs/1903.05987.
| ‘The 1st Workshop on Deep Learning Approaches for Low-Resource Natural Language Processing | ACL Member Portal’. https://www.aclweb.org/portal/content/1st-workshop-deep-learning-approaches-low-resource-natural-language-processing-1. |
Yang, Yi, and Jacob Eisenstein. ‘Part-of-Speech Tagging for Historical English’. http://arxiv.org/abs/1603.03144.
Monitoring and explaining semantic variation with deep contextual embeddings
Supervisor: Giovanni Colavizza, Kaspar Beelen and Kasra Hosseini (The Alan Turing Institute)
Words are malleable. In natural language, “meaning” is not permanently fixed, but tends to fluctuate as both the linguistic and historical contexts continuously change. This project focuses on algorithmic perspectives on semantic change, more specifically we scrutinize how recent advances language modelling help uncovering and understanding semantic variation (1) between social categories (such as political organisations) and (2) over time. The ability of neural networks to generate high-quality word representations has propelled deep learning to the centre of computational linguistics. In 2013, Mikolov (and colleagues) demonstrated how the vectors produced by a shallow neural network captured semantic and syntactic information of a word (Mikolov et al., 2013). Further research has shown that such vectors also capture historical (Hamilton et al., 2016), sociological (Garg et al., 2017) and ideological (Azarbonyad et al., 2017) aspects of language use.
Word2Vec and GloVe provide “static” word representations (i.e. they map each token to one vector), which clashes with the very context-sensitive dynamic of semantics. Only recently has a potential solution appeared on the horizon: the resurgence of (character-based) recurrent neural networks, has ushered in a shift towards “deep contextual” embeddings, which take into account the linguistic context to generate the representation of words and sentences (see ELMo (Peters et al., 2018) and BERT models (Devlin et al., 2018), for an overview see (Smith, 2019)).
Given the recent innovations in the field of representation learning, this project investigates the use of (fine-tuned) contextual models for studying semantic variation – taking both a sociological and historical approach. Data will consist of more than a century of historical newspapers (with extensive metadata, such as the places of circulation and the political leaning of the newspaper). This provides the ideal starting point for a fine-grained investigation, monitoring (and maybe even explaining) semantic change. The project uses data and benefits from experts from the Living with Machines project, based the The Alan Turing Institute and the British Library.
Further Reading
Azarbonyad, Hosein, Mostafa Dehghani, Kaspar Beelen, Alexandra Arkut, Maarten Marx, and Jaap Kamps. “Words are malleable: Computing semantic shifts in political and media discourse.” In Proceedings of the 2017 ACM on Conference on Information and Knowledge Management, pp. 1509-1518. ACM, 2017.
Devlin, Jacob, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. “Bert: Pre-training of deep bidirectional transformers for language understanding.” arXiv preprint arXiv:1810.04805 (2018).
Garg, Nikhil, Londa Schiebinger, Dan Jurafsky, and James Zou. “Word embeddings quantify 100 years of gender and ethnic stereotypes.” Proceedings of the National Academy of Sciences 115, no. 16 (2018): E3635-E3644.
Hamilton, William L., Jure Leskovec, and Dan Jurafsky. “Diachronic word embeddings reveal statistical laws of semantic change.” arXiv preprint arXiv:1605.09096 (2016).
Jo, Eun Seo, and Mark Algee-Hewitt. “The Long Arc of History: Neural Network Approaches to Diachronic Linguistic Change.” Journal of the Japanese Association for Digital Humanities 3, no. 1 (2018): 1-32.
Mikolov, Tomas, Kai Chen, Greg Corrado, and Jeffrey Dean. “Efficient estimation of word representations in vector space.” arXiv preprint arXiv:1301.3781 (2013).
Peters, Matthew E., Mark Neumann, Mohit Iyyer, Matt Gardner, Christopher Clark, Kenton Lee, and Luke Zettlemoyer. “Deep contextualized word representations.” arXiv preprint arXiv:1802.05365 (2018).
Smith, Noah A. “Contextual Word Representations: A Contextual Introduction.” arXiv preprint arXiv:1902.06006 (2019).
More context, less bias? Social bias in deep contextual word representations
Supervisor: Giovanni Colavizza and Kaspar Beelen (The Alan Turing Institute)
Emasculated kings, injected with a decent portion of femininity, happen to become queens–or at least, this was one of the more sensational findings of Mikolov et al. 2013, who demonstrated that the geometric properties where useful analogical reasoning (i.e. king is to man as ?? is to woman, could be computed by vector(king) - vector(man) + vector(woman). Findings reported in a subsequent stream of papers pointed out how the vectors trained on a large amount of text produced by humans, were showing similar forms of stereotypes and biases (Caliskan et al., 2018; Garg et al., 2017).
Most of the models up to 2018, generated “static” vectors, mapping words (or character sequences) to a specific vector, ignoring that a word can be polysemous and that its meaning often depends on the context in which it is used (see Smith, 2019 for a more extensive overview). The latest generation of embeddings, however, are contextualized, they generate a vector for a word based on its sentential context. As contextual models grow in popularity, more pre-trained models are released (such as ELMo (Peters et al., 2018) and BERT (Devlin et al., 2018,) among others). Even though the algorithms become increasingly complex, and the data on which that are trained continues to extend, the basic task remains one of language modelling, with humans telling computers what language should look like. For this reason, we investigate the extent to which these pre-trained models are prone to reproduce human-like biases, and what strategies could counter the potential effects on other downstream applications (Bolukbasi et al., 2016).
The project uses data and benefits from experts from the Living with Machines project, based the The Alan Turing Institute and the British Library.
Further reading:
Bolukbasi, Tolga, Kai-Wei Chang, James Y. Zou, Venkatesh Saligrama, and Adam T. Kalai. “Man is to computer programmer as woman is to homemaker? debiasing word embeddings.” In Advances in neural information processing systems, pp. 4349-4357. 2016.
Caliskan, Aylin, Joanna J. Bryson, and Arvind Narayanan. “Semantics derived automatically from language corpora contain human-like biases.” Science 356, no. 6334 (2017): 183-186.
Devlin, Jacob, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. “Bert: Pre-training of deep bidirectional transformers for language understanding.” arXiv preprint arXiv:1810.04805 (2018).
Hamilton, William L., Jure Leskovec, and Dan Jurafsky. “Diachronic word embeddings reveal statistical laws of semantic change.” arXiv preprint arXiv:1605.09096 (2016).
Garg, Nikhil, Londa Schiebinger, Dan Jurafsky, and James Zou. “Word embeddings quantify 100 years of gender and ethnic stereotypes.” Proceedings of the National Academy of Sciences 115, no. 16 (2018): E3635-E3644.
Mikolov, Tomas, Kai Chen, Greg Corrado, and Jeffrey Dean. “Efficient estimation of word representations in vector space.” arXiv preprint arXiv:1301.3781 (2013).
Peters, Matthew E., Mark Neumann, Mohit Iyyer, Matt Gardner, Christopher Clark, Kenton Lee, and Luke Zettlemoyer. “Deep contextualized word representations.” arXiv preprint arXiv:1802.05365 (2018).
Smith, Noah A. “Contextual Word Representations: A Contextual Introduction.” arXiv preprint arXiv:1902.06006 (2019).
Efficient Neural NLP
Supervisors: Jaap Kamps ILLC
Description
This is a project supported by Facebook Research and in collaboration with the University of Waterloo, Canada where we address efficiency aspects of neural NLP pipelines. We have various researchers and student assistants working on this in the Netherlands and Canada, and have space for multiple students to get involved as MSc AI graduation project (up to four students).
References
Facebook AI, 2019. Computationally Efficient Natural Language Processing request for proposals. https://research.fb.com/programs/research-awards/proposals/computationally-efficient-natural-language-processing-request-for-proposals/.
Hamed Zamani, Mostafa Dehghani, W. Bruce Croft, Erik Learned-Miller, and Jaap Kamps. 2018. From Neural Re-Ranking to Neural Ranking: Learning a Sparse Representation for Inverted Indexing. In Proceedings of the 27th ACM International Conference on Information and Knowledge Management (CIKM ‘18). ACM, New York, NY, USA, 497-506. DOI: https://doi.org/10.1145/3269206.3271800.
Who says What to Whom and Why?
Supervisors: Jaap Kamps ILLC
Description:
We have 200+ years of Parliamentary Proceedings for various countries, and have recent local city council proceedings from the Netherlands. These are meeting notes typically verbatim transcriptions of spoken language. We have extensive bibliographic data on most speakers (e.g., gender, date/place of birth, education level, etc) allowing for highly fine-grained analysis over various similarities and differences over demographics (e.g. gender, age, etc), over location (including representational systems in UK, Canada), or over time periods. We have space for multiple students to get involved as MSc AI graduation project (up to four students).
References
Political Mashup Projects, 2019. https://www.politicalmashup.nl.
Search Engine/API, 2019. http://search.politicalmashup.nl/.
Local city council data, 2019. https://waaroverheid.nl.
Computational Dialogue Modelling
Supervision: Raquel Fernández and other members of the Dialogue Modelling Group at ILLC
In the Dialogue Modelling Group at the ILLC, we carry out research at the interface of NLP, cognitive modelling, and AI. If you are interested in doing research in one of the following topics, you are very welcome to contact us:
- Conversational agents (well-motivated models of dialogue agents, not simply chatbots)
- Linguistic accommodation in dialogue and learning through interaction
- Visually grounded language and visual reasoning
- Computational psycholinguistics, including behavioural experiments with humans
- Language variation and change in communities of speakers
You can also take a look at our recent publications (available from our personal websites) to get a better idea of the kind of work we do.
We are interested in working with students who have:
- Experience with neural networks and deep learning architectures
- An interest in natural language and cognitively-inspired topics
- An interest in analyzing and understanding models’ activations and predictions
- Familiarity with (one of) the following libraries: pytorch, tensorflow, keras
Visually Grounded Dialogue with the PhotoBook Dataset
Supervision: Raquel Fernández and other members of the Dialogue Modelling Group at ILLC
Description
The past few years have seen an immense interest in developing and training computational agents for visually-grounded dialogue, the task of using natural language to communicate about visual input. The models developed for this task often focus on specific aspects such as image labelling, object reference, or question answering, but fail to produce consistent outputs over a conversation. We hypothesize that this shortcoming is mostly due to a missing representation of the participant’s shared common ground which develops and extends during an interaction. To facilitate progress towards more consistent and effective conversation, we have developed the PhotoBook Dataset. In the PhotoBook task, two participants are paired for an online multi-round image identification game. In this game they are shown collections of images which resemble the page of a photo book. On each page of the photo book, some of the images are present in the displays of both participants (the common images). The other images are each shown to one of the participants only (the different images). Three of the images in each display are highlighted through a yellow bar under the picture. The participants are tasked to mark these highlighted target images as either common or different by chatting with their partner. A full game consists of five consecutive rounds, where some of the previously displayed images will re-appear in later rounds, prompting participants to re-refer to them multiple times.
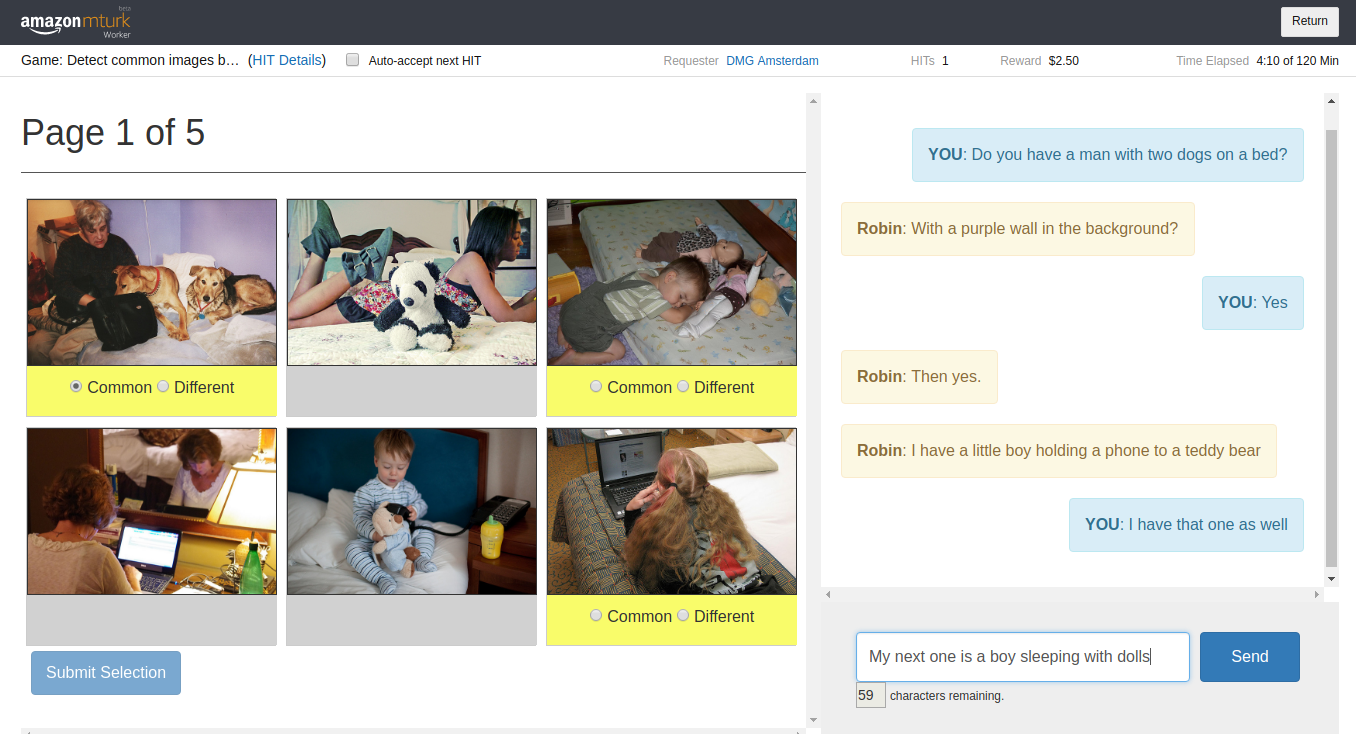
As a result of a carefully designed setup, dialogues in the PhotoBook dataset contain multiple descriptions of each of the target images, as illustrated in this example:

The dataset thus is a valuable resource for investigating participant cooperation, and specifically collaborative referring expression generation and resolution with respect to the conversation’s common ground. Several exciting research projects using this dataset are possible, depending on the student’s background, interests, and ideas. For example:
Reference resolution:
In Haber et al. (2019), we proposed a baseline reference resolution model that exploits the dialogue history. A research project can take this model as a starting point, analyse its behaviour in detail, and propose improved versions of the different model components (e.g., the representation of the dialogue history, the representation of the visual context, how linguistic and visual information and combined and exploited, etc).
Language generation:
Our analysis of the PhotoBook data shows that participants’ language use becomes more efficient over time: the speakers complete the task in progressively less time, use fewer utterances, and the utterances they use to refer to images become shorter and more abstract, and they reuse words that have been effective before (as shown in the example above). The focus of this research project would be on better understanding and then modelling this abstraction/compression process. This can be done from the perspective of language generation: given the current dialogue history, how would participants refer to a given image next?
Requisites:
- Experience with neural networks and deep learning architectures
- Interest in language and cognitively-inspired topics
- Interest in analyzing and understanding models’ activations and predictions
- Familiarity with (one of) the following libraries: pytorch, tensorflow, keras
Further reading:
- Janosch Haber, Tim Baumgärtner, Ece Takmaz, Lieke Gelderloos, Elia Bruni, and Raquel Fernández. The PhotoBook Dataset: Building Common Ground through Visually Grounded Dialogue. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics (ACL), 2019. https://www.aclweb.org/anthology/P19-1184
- Other related references are available in the PhotoBook paper.
A Relational Approach to Visual Question Answering: Reasoning about Objects’ Size
Supervisors: Raquel Fernández and Sandro Pezzelle (Dialogue Modelling Group ILLC)
Description
In recent years there has been a booming interest in exploring the abilities of multimodal deep learning models to answer questions that are grounded in an image (see, e.g., Visual Question Answering; Antol et al. 2015). To solve this task, models have to ‘understand’ the question and the image and to reason over their interaction. To force models learning strategies that go beyond simply learning biases or associations in the data, several synthetic datasets for visual reasoning tasks have been released (see, e.g., CLEVR; Johnson et al. 2017).
A (recently proposed visual reasoning task developed by our group challenges models to learn the meaning of size adjectives (‘big’, ‘small’) from visually-grounded contexts (MALeViC; Pezzelle and Fernández, 2019). Differently from standard approaches in language and vision treating size as a fixed attribute of objects (Johnson et al., 2017), in MALeViC what counts as ‘big’ or ‘small’ is defined contextually, based on a cognitively-motivated threshold function evaluating the size of all the relevant objects in a scene (Schmidt et al., 2009). In the most challenging version of the task, SET+POS, the subset of relevant objects (i.e., the reference set) comprises all the objects belonging to the same category as the queried one. Given a scene depicting a number of colored shapes (see Figure 1) and a sentence about one object’s size (e.g., ‘The white rectangle is a big rectangle’), models have to assess whether the sentence is true or false in that context; i.e., whether the white rectangle is big given the other rectangles in the scene.
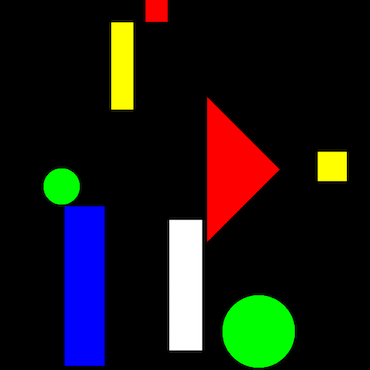 Figure 1. One example from the SET+POS task. The white rectangle is a big rectangle: True.
Figure 1. One example from the SET+POS task. The white rectangle is a big rectangle: True.
Overall, best-performing systems (e.g., FiLM; Perez et al., 2018) turn out to perform fairly well on the task, but to suffer when presented with scenes and questions about objects that are neither the biggest nor the smallest in the reference set (as in the example in Figure 1). This suggests that different strategies other than the expected one could be learned by the models, leaving open the issue of whether these systems genuinely develop an abstract meaning representation of ‘big’ and ‘small’. In this project, we propose the candidate student to experiment with the MALeViC dataset to investigate whether SoA models genuinely learn and understand relational information. This can be carried out in several ways, depending on the student’s background, interests, and ideas. For example:
Explaining Relations in Visual Question Answering
What image is wrong, and why? One approach could be to design and carry out a leave-one-out experiment where models are presented with a number of scenes (e.g., 4) all containing the same object (e.g., a white rectangle) and are asked to pick the scene where the size of the queried object (e.g., ‘big’) is different from its size in all other scenes (e.g., ‘small’). To assess what led to this decision, models are then asked to explain their decision, namely to generate a natural language explanation/description of the selected scene (similarly to Vondrick et al., 2016); i.e., “because… the white rectangle is big”. This would allow testing both whether a model can genuinely perform the task, and what information is exploited by the model to output that prediction.
Inferring Relations through Linguistic Interaction
Does asking (unrelated) questions make models more compositional? A striking result in Pezzelle and Fernández (2019) shows the inability of models to develop a representation of ‘big’, ‘small’ that can be applied compositionally to unseen objects. One approach to tackle this issue could be to design an experiment where models are given the chance to ask additional questions regarding one image. The idea is that having more information about either the target object or other objects in the scene makes models understand better the relations holding between objects. This can be setup as (A) a two-agent dialogue setting, or (B) a supervised learning setting where models are trained with more/less linguistic information about objects in the scene. In both cases, a thorough analysis will be devoted to understand which kind of extra linguistic information is more useful: about the target object, objects in the reference set, objects holding same/opposite relation, any object, etc.
Requisites:
- Experience with neural networks and deep learning architectures
- An interest in natural language and cognitively-inspired topics
- An interest in analyzing and understanding models’ activations and predictions
- Familiarity with (one of) the following libraries: pytorch, tensorflow, keras
References:
- Stanislaw Antol, Aishwarya Agrawal, Jiasen Lu, Mar- garet Mitchell, Dhruv Batra, C Lawrence Zitnick, and Devi Parikh. 2015. Vqa: Visual question answering. In Proceedings of the IEEE international conference on computer vision, pages 2425–2433.
- Justin Johnson, Bharath Hariharan, Laurens van der Maaten, Li Fei-Fei, C Lawrence Zitnick, and Ross Girshick. 2017a. Clevr: A diagnostic dataset for compositional language and elementary visual reasoning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 2901–2910.
- Ethan Perez, Florian Strub, Harm De Vries, Vincent Dumoulin, and Aaron Courville. 2018. Film: Visual reasoning with a general conditioning layer. In Thirty-Second AAAI Conference on Artificial Intelligence.
- Sandro Pezzelle and Raquel Fernández. 2019. Is the Red Square Big? MALeViC: Modeling Adjectives Leveraging Visual Contexts. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and 9th International Joint Conference on Natural Language Processing. Forthcoming.
- Lauren A Schmidt, Noah D Goodman, David Barner, and Joshua B Tenenbaum. 2009. How tall is tall? Compositionality, statistics, and gradable adjectives. In Proceedings of the 31st annual conference of the cognitive science society, pages 2759–2764. Citeseer.
- Vondrick, C., Oktay, D., Pirsiavash, H., & Torralba, A. (2016). Predicting motivations of actions by leveraging text. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (pp. 2997-3005).